The Three Pillars of JavaScript Bloat
Over the last couple of years, we’ve seen significant growth of the e18e community and a rise in performance focused contributions because of it. A large part of this is the “cleanup” initiative, where the community has been pruning packages which are redundant, outdated, or unmaintained.
One of the most common topics that comes up as part of this is “dependency bloat” - the idea that npm dependency trees are getting larger over time, often with long since redundant code which the platform now provides natively.
In this post, I want to briefly look at what I think are the three main types of bloat in our dependency trees, why they exist, and how we can start to address them.
1. Older runtime support (with safety and realms)
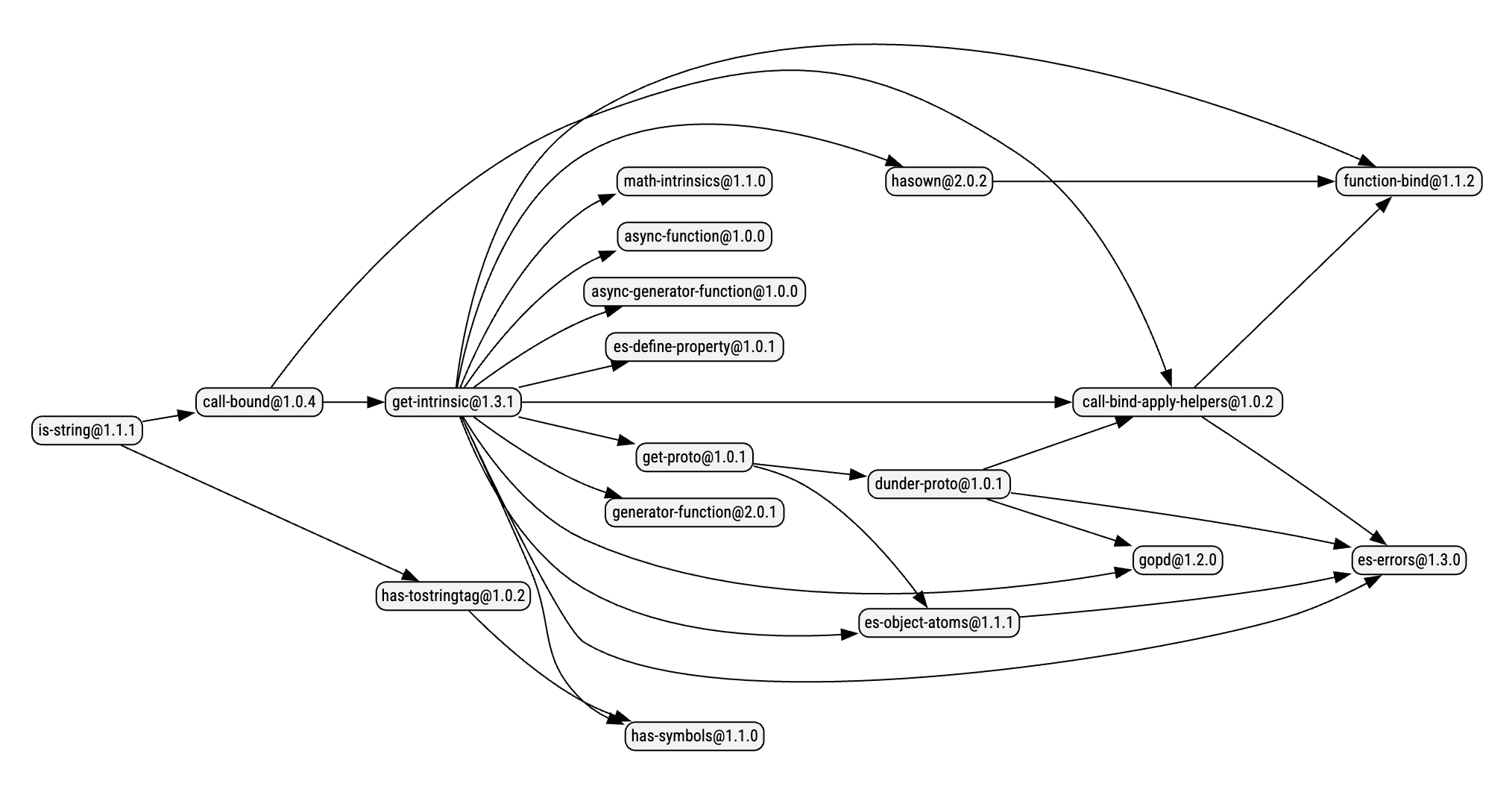
The graph above is a common sight in many npm dependency trees - a small utility function for something which seems like it should be natively available, followed by many similarly small deep dependencies.
So why is this a thing? Why do we need is-string instead of typeof checks? Why do we need hasown instead of Object.hasOwn (or Object.prototype.hasOwnProperty)? Three things:
- Support for very old engines
- Protection against global namespace mutation
- Cross-realm values
Support for very old engines
Somewhere in the world, some people apparently exist who need to support ES3 - think IE6/7, or extremely early versions of Node.js.1
For these people, much of what we take for granted today does not exist. For example, they don’t have any of the following:
Array.prototype.forEachArray.prototype.reduceObject.keysObject.defineProperty
These are all ES5 features, meaning they simply don’t exist in ES3 engines.
For these unfortunate souls who are still running old engines, they need to reimplement everything themselves, or be provided with polyfills.
Alternatively, what’d be really nice is if they upgraded.
Protection against global namespace mutation
The second reason for some of these packages is “safety”.
Basically, inside Node itself, there is a concept of “primordials”. These are essentially just global objects wrapped at startup and imported by Node from then on, to avoid Node itself being broken by someone mutating the global namespace.
For example, if Node itself uses Map and we re-define what Map is - we can break Node. To avoid this, Node keeps a reference to the original Map which it imports rather than accessing the global.
You can read more about this here in the Node repo.
This makes a lot of sense for an engine, since it really shouldn’t fall over if a script messes up the global namespace.
Some maintainers also believe this is the correct way to build packages, too. This is why we have dependencies like math-intrinsics in the graph above, which basically re-exports the various Math.* functions to avoid mutation.
Cross-realm values
Lastly, we have cross-realm values. These are basically values you have passed from one realm to another - for example, from a web page to a child <iframe> or vice versa.
In this situation, a new RegExp(pattern) in an iframe, is not the same RegExp class as the one in the parent page. This means window.RegExp !== iframeWindow.RegExp, which of course means val instanceof RegExp would be false if it came from the iframe (another realm).
For example, I am a maintainer of chai, and we have this exact issue. We need to support assertions happening across realms (since a test runner may run tests in a VM or iframe), so we can’t rely on instanceof checks. For that reason, we use Object.prototype.toString.call(val) === '[object RegExp]' to check if something is a regex, which works across realms since it doesn’t rely on the constructor.
In the graph above, is-string is basically doing this same job in case we passed a new String(val) from one realm to another.
Why this is a problem
All of this makes sense for a very small group of people. If you’re supporting very old engines, passing values across realms, or want protection from someone mutating the environment - these packages are exactly what you need.
The problem is that the vast majority of us don’t need any of this. We’re running a version of Node from the last 10 years, or using an evergreen browser. We don’t need to support pre-ES5 environments, we don’t pass values across frames, and we uninstall packages which break the environment.2
These layers of niche compatibility somehow made their way into the “hot path” of everyday packages. The tiny group of people who actually need this stuff should be the ones seeking out special packages for it. Instead, it is reversed and we all pay the cost.
2. Atomic architecture
Some folks believe that packages should be broken up to an almost atomic level, creating a collection of small building blocks which can later be re-used to build other higher level things.
This kind of architecture means we end up with graphs like this:
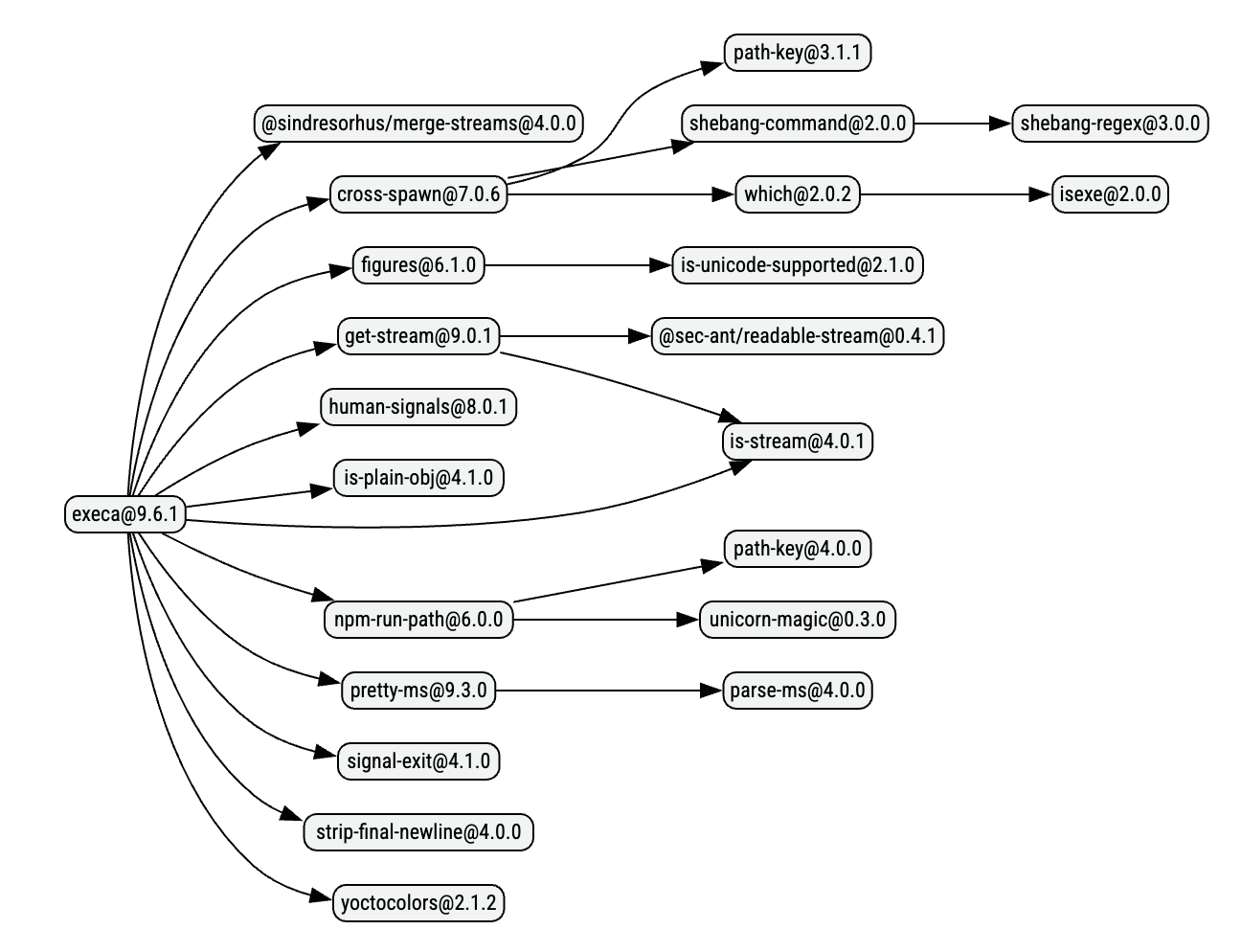
As you can see, the most granular snippets of code have their own packages. For example, shebang-regex is the following at the time of writing this post:
const shebangRegex = /^#!(.*)/;
export default shebangRegex;
By splitting code up to this atomic level, the theory is that we can then create higher level packages simply by joining the dots.
Some examples of these atomic packages to give you an idea of the granularity:
arrify- Converts a value to an array (Array.isArray(val) ? val : [val])slash- Replace backslashes in a file-system path with/cli-boxes- A JSON file containing the edges of a boxpath-key- Get thePATHenvironment variable key for the current platform (PATHon Unix,Pathon Windows)onetime- Ensure a function is only called onceis-wsl- Check ifprocess.platformislinuxandos.release()containsmicrosoftis-windows- Check ifprocess.platformiswin32
If we wanted to build a new CLI for example, we could pull a few of these in and not worry about implementation. We don’t need to do env['PATH'] || env['Path'] ourselves, we can just pull a package for that.
Why this is a problem
In reality, most or all of these packages did not end up as the reusable building blocks they were meant to be. They’re either largely duplicated across various versions in a wider tree, or they’re single-use packages which only one other package uses.
Single use packages
Let’s take a look at some of the most granular packages:
shebang-regexis used almost solely byshebang-commandby the same maintainercli-boxesis used almost solely byboxenandinkby the same maintaineronetimeis used almost solely byrestore-cursorby the same maintainer
Each of these having only one consumer means they’re equivalent of inline code but cost us more to acquire (npm requests, tar extraction, bandwidth, etc.).
Duplication
Taking a look at nuxt’s dependency tree, we can see a few of these building blocks duplicated:
is-docker(2 versions)is-stream(2 versions)is-wsl(2 versions)isexe(2 versions)npm-run-path(2 versions)path-key(2 versions)path-scurry(2 versions)
Inlining them doesn’t mean we no longer duplicate the code, but it does mean we don’t pay the cost of things like version resolution, conflicts, cost of acquisition, etc.
Inlining makes duplication almost free, while packaging makes it expensive.
Larger supply chain surface area
The more packages we have, the larger our supply chain surface area is. Every package is a potential point of failure for maintenance, security, and so on.
For example, a maintainer of many of these packages was compromised last year. This meant hundreds of tiny building blocks were compromised, which meant the higher level packages we actually install were also compromised.
Logic as simple as Array.isArray(val) ? val : [val] probably doesn’t need its own package, security, maintenance, and so on. It can just be inlined and we can avoid the risk of it being compromised.
Similar to the first pillar, this philosophy made its way into the “hot path” and probably shouldn’t have. Again, we all pay the cost to no real benefit.
3. “Ponyfills” that overstayed their welcome

If you’re building an app, you might want to use some “future” features your chosen engine doesn’t support yet. In this situation, a polyfill can come in handy - it provides a fallback implementation where the feature should be, so you can use it as if it were natively supported.
For example, temporal-polyfill polyfills the new Temporal API so we can use Temporal regardless of if the engine supports it or not.
Now, if you’re building a library instead, what should you do?
In general, no library should load a polyfill as that is a consumer’s concern and a library shouldn’t be mutating the environment around it. As an alternative, some maintainers choose to use what’s called a ponyfill (sticking to the unicorns, sparkles and rainbows theme).
A ponyfill is basically a polyfill you import rather than one which mutates the environment.
This kinda works since it means a library can use future tech by importing an implementation of it which passes through to the native one if it exists, and uses the fallback otherwise. None of this mutates the environment, so it is safe for libraries to use.
For example, fastly provides @fastly/performance-observer-polyfill, which contains both a polyfill and ponyfill for PerformanceObserver.
Why this is a problem
These ponyfills did their job at the time - they allowed the library author to use future tech without mutating the environment and without forcing the consumer to know which polyfills to install.
The problem comes when these ponyfills outstay their welcome. When the feature they fill in for is now supported by all engines we care about, the ponyfill should be removed. However, this often doesn’t happen and the ponyfill remains in place long after it’s needed.
We’re now left with many, many packages which rely on ponyfills for features we’ve all had for a decade now.
For example:
globalthis- ponyfill forglobalThis(widely supported in 2019, 49M downloads a week)indexof- ponyfill forArray.prototype.indexOf(widely supported in 2010, 2.3M downloads a week)object.entries- ponyfill forObject.entries(widely supported in 2017, 35M downloads a week)
Unless these packages are being kept alive because of Pillar 1, they’re usually still used just because nobody ever thought to remove them.
When all long-term support versions of engines have the feature, the ponyfill should be removed.4
What can we do about it?
Much of this bloat is so deeply nested in dependency trees today that it is a fairly hefty task to unravel it all and get to a good place. It will take time, and it will take a lot of effort from maintainers and consumers.
Having said that, I do think we can make significant progress on this front if we all work together.
Start asking yourself, “why do I have this package?” and “do I really need it?”.
If you find something which seems redundant, raise an issue with the maintainer asking if it can be removed.
If you encounter a direct dependency which has many of these issues, have a look for an alternative which doesn’t. A good start for that is the module-replacements project.
Using knip to remove unused dependencies
knip is a great project which can help you find and remove unused dependencies, dead code, and much more. In this case, it can be a great tool to help you find and remove dependencies you no longer use.
This doesn’t solve the problems above necessarily, but is a great starting point to help clean up the dependency tree before doing more involved work.
You can read more about how knip deals with unused dependencies in their documentation.
Using the e18e CLI to detect replaceable dependencies
The e18e CLI has a super useful analyze mode to determine which dependencies are no longer needed, or have community recommended replacements.
For example, if you get something like this:
$ npx @e18e/cli analyze
...
│ Warnings:
│ • Module "chalk" can be replaced with native functionality. You can read more at
│ https://nodejs.org/docs/latest/api/util.html#utilstyletextformat-text-options. See more at
│ https://github.com/es-tooling/module-replacements/blob/main/docs/modules/chalk.md.
...
Using this, we can quickly identify which direct dependencies can be cleaned up. We can also then use the migrate command to automatically migrate some of these dependencies:
$ npx @e18e/cli migrate --all
e18e (cli v0.0.1)
┌ Migrating packages...
│
│ Targets: chalk
│
◆ /code/main.js (1 migrated)
│
└ Migration complete - 1 files migrated.
In this case, it will migrate from chalk to picocolors, a much smaller package which provides the same functionality.
In the future, this CLI will even recommend based on your environment - for example, it could suggest the native styleText instead of a colours library if you’re running a new enough Node.
Using npmgraph to investigate your dependency tree
npmgraph is a great tool to visualize your dependency tree and investigate where bloat is coming from.
For example, let’s take a look at the bottom half of ESLint’s dependency graph as of writing this post:
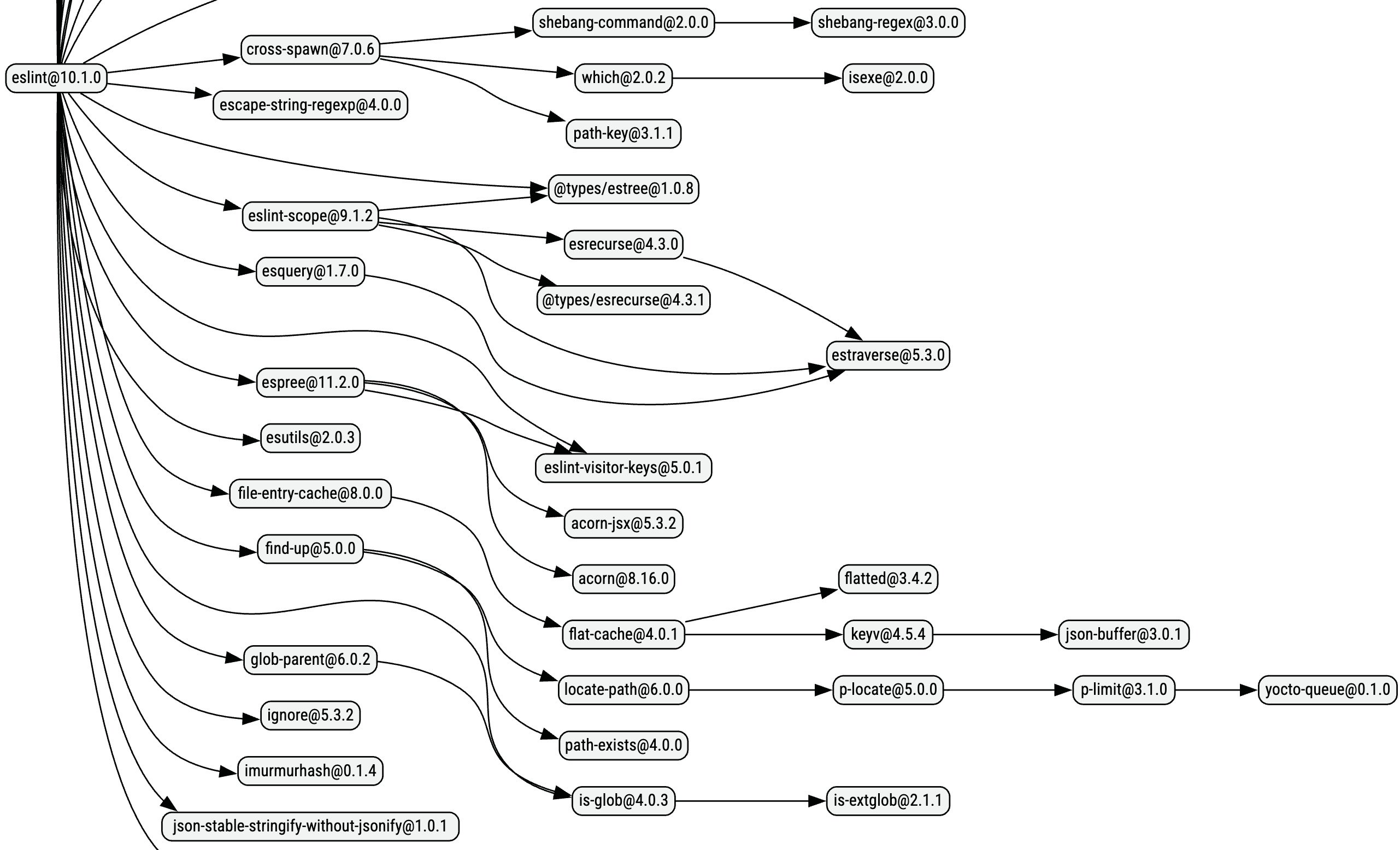
We can see in this graph that the find-up branch is isolated, in that nothing else uses its deep dependencies. For something as simple as an upwards file-system traversal, maybe we don’t need 6 packages. We can then go look for an alternative, such as empathic which has a much smaller dependency graph and achieves the same thing.
Module replacements
The module replacements project is being used as a central data set for the wider community to document which packages can be replaced with native functionality, or more performant alternatives.
If you’re ever in need of an alternative or just want to check your dependencies, this data set is great for that.
Similarly, if you come across packages in your tree which are made redundant by native functionality, or just have better battle-tested alternatives, this project is definitely a great place to contribute that so others can benefit from it.
Paired with the data, there’s also a codemods project which provides codemods to automatically migrate some of these packages to their suggested replacements.
Closing Thoughts
We all pay the cost for an incredibly small group of people to have an unusual architecture they like, or a level of backwards compatibility they need.
This isn’t necessarily a fault of the people who made these packages, as each person should be able to build however they want. Many of them are an older generation of influential JavaScript developers - building packages in a darker time where many of the nice APIs and cross-compatibility we have today didn’t exist. They built the way they did because it was possibly the best way at the time.
The problem is that we never moved on from that. We still download all of this bloat today even though we’ve had these features for several years.
I think we can solve this by reversing things. This small group should pay the cost - they should have their own special stack pretty much only they use. Everyone else gets the modern, lightweight, and widely supported code.
Hopefully things like e18e and npmx can help with that through documentation, tooling, etc. You can also help by taking a closer look at your dependencies and asking “why?”. Raise issues with your dependencies asking them if, and why they need these packages anymore.
We can fix it.
Footnotes
-
I believe there are people who need such old engines, but would love to see some examples ↩
-
Most of this bloat is from a time when it was probably necessary since the platform obviously wasn’t as feature-rich back then. I think it was probably the right decision/architecture at the time. ↩
-
Most mentioned years of support are from MDN, or if it pre-dates MDN, from the compat data ↩
-
“Ponyfill” stuff in general is an unsettled topic, really. I think we should drop them once LTS is achieved, but others do disagree and want them “forever”. ↩